
When I was lucky enough to be working at Pottermore, there was a whole bunch of ‘fact checkers’ who knew the Harry Potter universe inside out, and when EW originally pitched to Pottermore Gus proposed and prototyped a ‘narrative engine’ for exploring the story.
As a personal side project I thought it would be great to try and understand the time over which the Pottermore universe unfolds and see if there were any interface metaphors or concepts that could be used to make the content of the site more discoverable.
Pottermore was amazing because the ‘Potterverse’ (extended fictional universes) fans are so engaged and enthusiastic about the story and the narrative. But it also meant every one was brimming over with ideas and interface ideas for the site.
I wanted to explore the most appropriate interface metaphors that would allow the user to discover and explore the richness of the growing Wizarding World.
Chronology, moments and a timeline
Harry Potter has a few ways of measuring time. There is the book time as expressed in the ‘moments’ which also was how the old game based website was based. There is also real time, the Harry Potter takes place from 1991 to 1998. Characters age and they attend Hogwarts which of course has term time. So each book is like a school year as well.
The new film, Fantastic Beasts and Where to Find them, the story will feature Newt Scamander as a main character and will be set in New York, 70 years before Harry’s story starts (1920’s New York). The introductory text we have so far sketches out the development of magic in America around actual historical events.
The easiest ‘node’ to develop in a timeline is events or moments where characters, locations, creatures, and objects (wands and potions etc) all interact.
Looking at histography, datum, and facebook timeline, suggested a chronological linear time based interface could work. But to create an effective interface was difficult as nothing really happened during the school holidays, leaving a lot of the interface empty. The moments also tended to cluster as the drama ebbed and flowed within the school term. So whilst a Facebook timeline metaphor provides a framework for the key narrative moments, it didn’t appear create a useful interface.

Data, taxonomy, and hierarchy
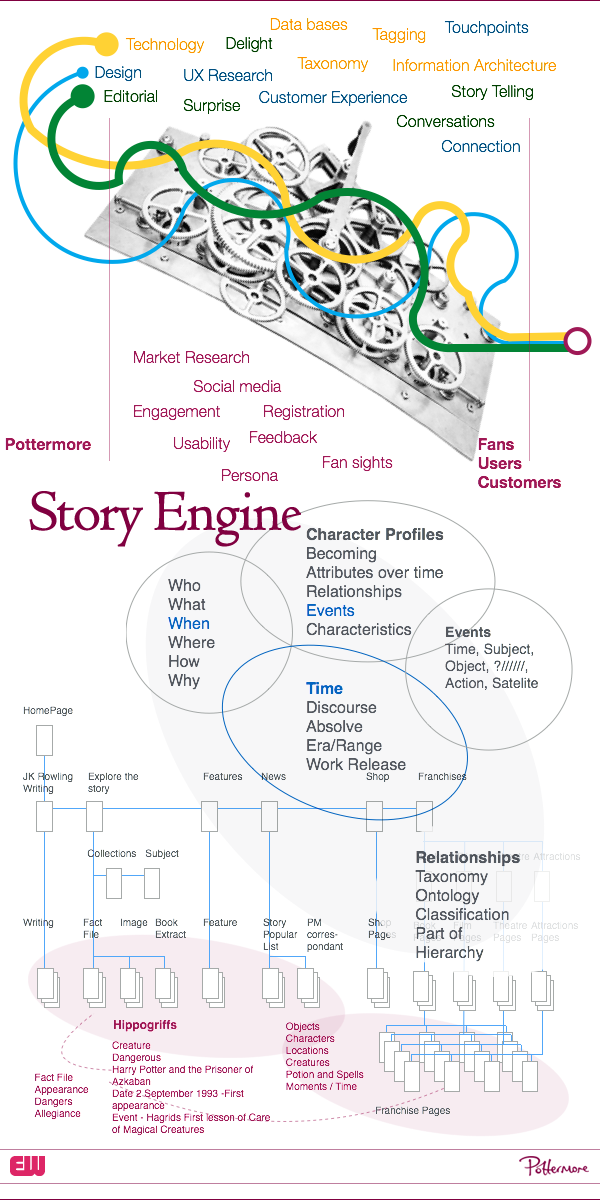
Pottermore has a fact file section in the Explore Pottermore section. Which provides additional information for the fans about all aspects of the ‘Potterverse’. But the data has lots of overlaps. So a wand has who owned it, or used it, a charm has most famous wizard who uses it, a location can have a resident or owner, and a character of course relates to a person. So one character could connect all of the above. But at the moment the CMS doesn’t allow you to tag with ‘Key person’. In order to guarantee as much flexibility on the site and make it as future proof as possible we need to think about all the types of data we are going to be showing and what the relationship is between them. I don’t know if there is value to working out a ‘classification’ system for Pottermore.
So I produced a number of ideas to explore the different ways of organising the data. Moving from a traditional tree structure, like a hierarchical family tree with each person being a node. Would Harry Potter be the root node spreading through ‘The Trio’ of Ron and Hermione.
Introducing tags to the posts would really help the user find new routes around the site. Tags are most used in blogs. Blogs are otherwise a flat, chronologically sorted list of content pieces. Tags added an effective way to denote the main focus topics of a given article while also providing a useful filter criteria. By combining multiple tags in a filter it becomes possible in many cases to quickly drill down. Moreover, as each tag essentially stands on its own, adding a new tag is trivial. Simply begin using the new tag and it exists. This is simpler than a tree structure, where it is necessary to decide where in the tree a new topic best fits.
Facets would be great for grouping things. Facets have become especially popular in e-commerce sites to allow users to filter based on multiple dimensions in the order they prefer. However, they basically require content to be somewhat structured to be effective. Whereas chapters in a book usually just provide a title following a lot of text, for facets, one should further work to split the text into more structured pieces of information. Just like with tags, with facets it becomes possible to find the same piece of information in different places. References, are distinct from the data, but allow you to build really complex data structure, like graph based systems. I spent a lot of time talking with Gus about this, but we never got round to building anything this complex.